5.4.1 正则表达式产生的正则语法
通过使用图Fig5.17给出的转换方式,可以将正则表达式转换为正则语法。转换中的T代表中间的非终结符,被选择用来刷新转换的每个应用;α代表处非终结符之外的任意正则表达式,其后可能接着非终结符。如果α为空,当它单独出现在右手侧时应该用ε替换。
正则表达式到正则语法的扩展对于从正则表达式得到DFA很有帮助,对词汇分分析器如lex中是必须的。生成的正则语法可以直接用于NFA,它可用于生成上述的DFA。还有另一种方法从正则表达式创建一个NFA,但是这需要对正则表达式进行一些预处理;见Thompson [140]。
我们将用表达式 *(ab) (p|q)+**说明该方法。我们的方法也将适用于包含正则表达式的正则语法(如 A → ab∗cB),实际上我们马上就要将正则表达式转换为此类语法:
尽管图Fig5.17中的表用T来生成非终结符,但我们使用例子中的A,B,C...(比起T1、T2、T3...没那么易混淆)。持续转换直到所有规则都是(扩展的)标准形式。
第一个转换被应用到 P→R *α,用以下替换__Ss->(ab) *(p|q)+__:

第一个规则已经转换为目标形式,并标记了✔。P → (R)α和P → aα的转换方式应用到A->(ab)A上,就有了:

P → R+α的转换应用到**A->(p|q)+**得到:
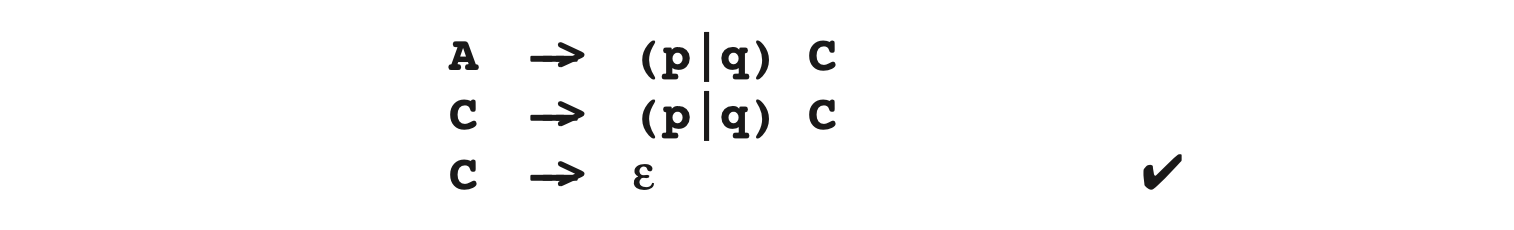
ε源于这样一个事实,A->(p|q)+中的 (p|q)+后面没接任何东西(这意味着ε是唯一的)。那么A->(p|q)C和C->(p|q)C就很容易分解成:


完整的扩展标准版本见图Fig5.18;NFA和DFA可以使用5.3.1节(此处未显示)的方式生成。