3.5.2 搜索技术
第三种分类解析技术的方式涉及到在指导解析自动机通过其所有可能性找到一个或所有解析结果的搜索过程。
总的来说有两个方法来解决问题,其中有几个备选方案其核心都是:深度优先搜索和广度优先搜索。
-
在深度优先搜索中,我们的注意力集中在一个解决一半的问题上。如果在一个给定点P上出现分叉这样的问题,我们先将其中一条放在一边等待稍后处理并继续处理另一条。如果这条路最后失败了(或者即便是成功了,但是我们想要的是全部的结果),我们就回到点P在继续处理刚才被放在一边的那条。这就是所谓的回溯。
-
在广度优先搜索中,我们保留了一套解决一半问题的集合。从这个集合中我们计算出一个新的(更好的)解决一般问题的集合,通过检查每个已有的解决了一半的问题;对每一个选项,我们在新集合中创建一个副本。实际上,这个集合最终会包含所有的解决方案。
深度优先搜索的优点是它需要与已存在的问题数量成正比的内存空间,而不像广度优先搜索,它需要的内存是程指数增长的。广度优先搜索的优点是它将首先找到最简单的方案。这两种方法都需要在原则上服从指数分布的时间。如果我们想要更有效的(并且不接受指数分布要求),我们需要一些手段来限制搜索。搜索技术的更多信息,可以在任意一本关于算法的书上找到,例如Sedgewick [417] or Goodrich and Tamassia [416]。
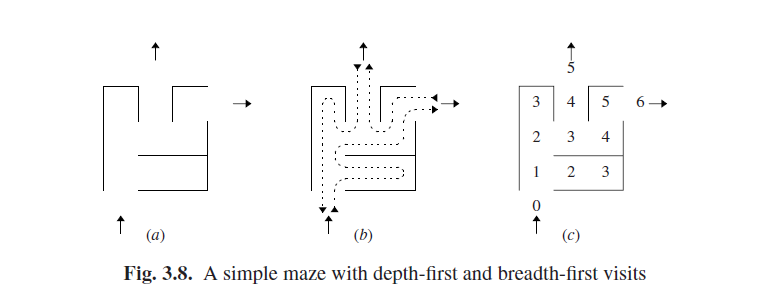
这些搜索技术根本不限于解析技术,而是可以在广泛的范围内使用。一种传统的用法是找到迷宫的出口。图Fig 3.8(a)是一个简单的有一个入口和两个出口的迷宫,Fig 3.8(b)描绘了深度优先搜索将会采取的路径;这对行走其中的人类来说是唯一的选:他不能复制他自己获取迷宫。死胡同让深度优先搜索回溯到最近的一条没有尝试过的选择。如果搜索者也回溯每一个出口,那他将发现所有的出口。Fig 3.8(c)显示了广度优先搜索在每个阶段已经检查过的空间。死胡同(阶段3)将导致搜索分之被丢弃。广度优先搜索将会找到最快的捷径(最短解决方案)。如果它持续下去直到没有分支剩下,那也将找到全部的出口(所有解决方案)。