4.1.3 从Unger方法中获得解析林语法
在进行Unger解析时构建一个解析林语法是非常容易的:所需要的只是在每一个尝试分区中向解析林添加一个规则。例如,4.1.1节中的第一个分区(图Fig4.2第6行)向语法解析林添加了规则:
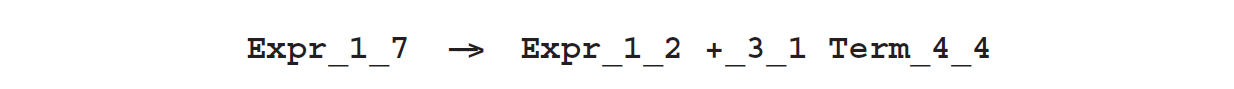
分区的每一个段(segment)和分区本身都已经被一个特定的非终结符设定好了,其名称由其原始名称和段的起点加长度组成。这甚至适用于原始终结符,因为上面的分区声明了**+是位置3的+**(从1开始计算输入标记)。
图Fig4.2的第一部分添加了规则:
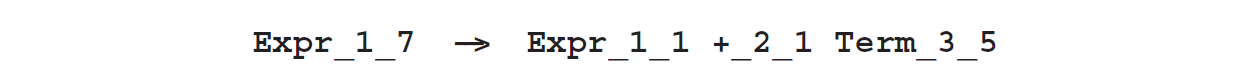
但犹豫输入并没有包含**+_ 2_ 1**,以及在位置2不包含**+**,所以这个规则可以被马上排除。或者可以说,它包含一个未定义的终结符,然后2.9.5节的语法清理算法将为我们删除它。同样,4.1.1节中中所述的尝试添加了规则:

这再次包含了一个未定义的终结符,i_1_2。(第一个可选因子,因子--->(Expr),是不适用的,因为它需要将Factor_1_2分成3分,而目前在4.1.1节我们还不允许使用ε规则。)
我们看到,Unger解析作为一个自顶向下解析方法,带来了大量的未定义非终结符(和ditto终结符);这代表了自顶向下过程中没有实现的假设。

解析过程产生了一个又294条规则的解析林语法,我们在这里就不展示了。整理之后就是图Fig4.5了,有11条规则。就可以很清晰的看到,它与4.1.1节最后的字符串**(i+i)×i**得出的解析相当。